
Les DataFrames Pandas
Un DataFrame pandas est une structure de données tabulaire :
- lignes → observations
- colonnes → variables
- index → identifiant des lignes
👉 Définition formelle
Un DataFrame est un ensemble de Series pandas partageant le même index (Chaque colonne est une Series)
Exemple
Exemples de séries ayant le même index :
| Index | Year |
|---|---|
| USA | 1776 |
| CANADA | 1867 |
| MEXICO | 1821 |
| Index | Pop |
|---|---|
| USA | 328 |
| CANADA | 38 |
| MEXICO | 126 |
| Index | GDP |
|---|---|
| USA | 20.5 |
| CANADA | 1.7 |
| MEXICO | 1.22 |
| Index | Year | Pop | GDP |
|---|---|---|---|
| USA | 1776 | 328 | 20.5 |
| CANADA | 1867 | 38 | 1.7 |
| MEXICO | 1821 | 126 | 1.22 |
Fichier Python associé
"""
dataframe_basics.py
==================
Bases des DataFrames Pandas
Ce script couvre :
- La création de DataFrames à partir de tableaux ou de fichiers CSV
- L'accès aux colonnes et aux lignes
- La manipulation des données : création, suppression, modification
"""
import pandas as pd
import numpy as np
# ======================================================
# 1. Création d'un DataFrame à partir d'objets Python
# ======================================================
# Fixer la seed pour reproduire les mêmes nombres aléatoires
np.random.seed(101)
# Création d'un tableau 4x3 avec des entiers aléatoires entre 0 et 100
mydata = np.random.randint(0, 101, (4, 3))
print("Tableau de données aléatoires :\n", mydata, "\n")
# Définir un index pour les lignes (exemple : abréviations des états)
myindex = ['CA', 'NY', 'AZ', 'TX']
# Définir les noms des colonnes
mycolumns = ['Jan', 'Feb', 'Mar']
# Création du DataFrame à partir des données uniquement
df = pd.DataFrame(data=mydata)
print("DataFrame avec index et colonnes par défaut :\n", df, "\n")
# Création du DataFrame avec un index personnalisé
df = pd.DataFrame(data=mydata, index=myindex)
print("DataFrame avec index personnalisé :\n", df, "\n")
# Création du DataFrame avec index et colonnes personnalisés
df = pd.DataFrame(data=mydata, index=myindex, columns=mycolumns)
print("DataFrame complet avec index et colonnes :\n", df, "\n")
# Obtenir des informations sur le DataFrame
print("Informations générales sur le DataFrame :")
df.info()
print("\n")
# ======================================================
# 2. Lecture d'un fichier CSV dans un DataFrame
# ======================================================
# Lecture du fichier 'tips.csv' (assurez-vous qu'il est dans le même dossier)
df = pd.read_csv('./data/tips.csv')
print("Lecture du fichier CSV 'tips.csv' :\n", df.head(), "\n")
# Obtenir des informations de base sur le DataFrame
print("Colonnes :", df.columns)
print("Index :", df.index)
print("Premières lignes :", df.head(3))
print("Dernières lignes :", df.tail(3))
print("Résumé info :")
df.info()
print("Nombre de lignes :", len(df))
print("Statistiques descriptives :")
print(df.describe().transpose())
print("\n")
# ======================================================
# 3. Sélection et manipulation des colonnes
# ======================================================
# Saisir une seule colonne
print("Exemple d'accès à une colonne :")
print(df['total_bill'])
print("Type :", type(df['total_bill']), "\n")
# Saisir plusieurs colonnes
print("Accès à plusieurs colonnes :")
print(df[['total_bill', 'tip']], "\n")
# Créer de nouvelles colonnes
df['tip_percentage'] = 100 * df['tip'] / df['total_bill']
df['price_per_person'] = df['total_bill'] / df['size']
# Arrondir les valeurs à 2 décimales
df['price_per_person'] = np.round(df['price_per_person'], 2)
print("DataFrame avec nouvelles colonnes :\n", df.head(), "\n")
# Supprimer une colonne
df = df.drop('tip_percentage', axis=1)
print("DataFrame après suppression de la colonne 'tip_percentage' :\n", df.head(), "\n")
# ======================================================
# 4. Bases de l'index
# ======================================================
# Vérifier l'index actuel
print("Index actuel :", df.index, "\n")
# Définir une colonne comme index
df = df.set_index('Payment ID')
print("DataFrame après avoir défini 'Payment ID' comme index :\n", df.head(), "\n")
# Réinitialiser l'index (transforme l'index en colonne)
df = df.reset_index()
print("DataFrame après réinitialisation de l'index :\n", df.head(), "\n")
# ======================================================
# 5. Manipulation des lignes (rows)
# ======================================================
# Définir à nouveau 'Payment ID' comme index pour manipuler les lignes
df = df.set_index('Payment ID')
# Accès à une seule ligne
print("Accès à la première ligne par position (iloc) :\n", df.iloc[0], "\n")
print("Accès à une ligne par label (loc) :\n", df.loc['Sun2959'], "\n")
# Accès à plusieurs lignes
print("Accès à plusieurs lignes par position :\n", df.iloc[0:4], "\n")
print("Accès à plusieurs lignes par label :\n", df.loc[['Sun2959','Sun5260']], "\n")
# Supprimer une ligne par label
df_temp = df.drop('Sun2959', axis=0)
print("DataFrame après suppression de la ligne 'Sun2959' (temporaire) :\n", df_temp.head(), "\n")
# Insérer une nouvelle ligne (rarement utilisé en pratique)
# Copier une ligne existante
one_row = df.iloc[0]
# Attention : .append() est déprécié depuis Pandas 2.0, utiliser pd.concat() à la place
df = pd.concat([df, one_row.to_frame().T])
print("DataFrame après ajout d'une nouvelle ligne :\n", df.tail(), "\n")
# ======================================================
# 6. Filtrage conditionnel
# ======================================================
print("=== Filtrage conditionnel : une seule condition ===\n")
# Exemple : total_bill > 40
condition1 = df['total_bill'] > 40
print("Série booléenne pour total_bill > 40 :\n", condition1.head(), "\n")
# Appliquer le filtre
df_filtered1 = df[condition1]
print("Lignes où total_bill > 40 :\n", df_filtered1.head(), "\n")
# Filtrage direct sans variable intermédiaire
df_filtered_direct = df[df['total_bill'] > 40]
print("Filtrage direct total_bill > 40 :\n", df_filtered_direct.head(), "\n")
# Exemple : filtrage sur une colonne catégorielle
df_filtered2 = df[df['sex'] == 'Male']
print("Lignes où sex = 'Male' :\n", df_filtered2.head(), "\n")
# ======================================================
print("=== Filtrage conditionnel : conditions multiples ===\n")
# Exemple : total_bill > 30 ET sex = 'Male'
df_filtered_and = df[(df['total_bill'] > 30) & (df['sex'] == 'Male')]
print("total_bill > 30 ET sex = 'Male' :\n", df_filtered_and.head(), "\n")
# Exemple : total_bill > 30 OU sex = 'Female'
df_filtered_or = df[(df['total_bill'] > 30) | (df['sex'] == 'Female')]
print("total_bill > 30 OU sex = 'Female' :\n", df_filtered_or.head(), "\n")
# ======================================================
print("=== Filtrage conditionnel : plusieurs valeurs avec isin ===\n")
# Exemple : filtrer les jours du week-end (Saturday, Sunday)
weekend_days = ['Saturday', 'Sunday']
df_filtered_weekend = df[df['day'].isin(weekend_days)]
print("Lignes correspondant au week-end :\n", df_filtered_weekend.head(), "\n")
# Ajouter un jour supplémentaire (Friday)
days_filter = ['Friday', 'Saturday', 'Sunday']
df_filtered_days = df[df['day'].isin(days_filter)]
print("Lignes correspondant à Friday, Saturday ou Sunday :\n", df_filtered_days.head(), "\n")
# ======================================================
# 7. Méthodes utiles : apply sur une seule colonne
# ======================================================
print("=== Méthode apply : appliquer une fonction custom sur une colonne ===\n")
# Exemple 1 : extraire les 4 derniers chiffres d'une colonne 'cc_number' (numéro de carte)
# On crée une fonction custom
def last_four(num):
"""Retourne les 4 derniers chiffres d'un nombre en tant que chaîne"""
return str(num)[-4:]
# Vérification rapide de la fonction
print("Test fonction last_four sur un nombre :", last_four(123456789), "\n")
# Application de la fonction à la colonne 'cc_number' via apply
# Attention : cette colonne doit exister dans votre DataFrame df
if 'cc_number' in df.columns:
df['last_four'] = df['cc_number'].apply(last_four)
print("Exemple d'application de last_four sur la colonne 'cc_number' :\n", df[['cc_number', 'last_four']].head(), "\n")
else:
print("Colonne 'cc_number' non présente dans df. Passez à l'exemple suivant.\n")
# Exemple 2 : catégoriser le total_bill en $ (low, medium, high) avec apply
def categorize_price(price):
"""Retourne un label $ en fonction du prix"""
if price < 10:
return '$'
elif 10 <= price < 30:
return '$$'
else:
return '$$$'
# Application de la fonction sur la colonne 'total_bill'
df['price_category'] = df['total_bill'].apply(categorize_price)
print("DataFrame avec nouvelle colonne 'price_category' :\n", df[['total_bill', 'price_category']].head(), "\n")
# Note pédagogique :
print("""
💡 Points clés sur l'utilisation de apply sur une seule colonne :
- La fonction passée à apply doit prendre en entrée **une seule valeur** (une ligne de la série)
- La fonction doit **retourner une seule valeur**, pas une série
- Très utile pour transformer ou créer de nouvelles colonnes à partir d'une colonne existante
""")
# ======================================================
# 8. Méthodes utiles : apply sur des colonnes multiples
# ======================================================
print("=== Méthode apply : appliquer une fonction sur plusieurs colonnes ===\n")
# ------------------------------------------------------
# Rappel : expression lambda
# ------------------------------------------------------
# lambda x: x * 2
# Fonction anonyme à usage unique, très utilisée avec apply
# ------------------------------------------------------
# Exemple : évaluer la qualité du pourboire
# Colonnes utilisées : total_bill et tip
# ------------------------------------------------------
def tip_quality(total_bill, tip):
"""
Évalue la qualité du pourboire en fonction du ratio tip / total_bill
"""
if (tip / total_bill) > 0.25:
return "Généreux"
else:
return "Standard"
# Test rapide de la fonction
print("Test tip_quality :", tip_quality(16.99, 1.01), "\n")
# ------------------------------------------------------
# Méthode 1 : apply + lambda (axis=1)
# ------------------------------------------------------
df['tip_quality_apply'] = df[['total_bill', 'tip']].apply(
lambda row: tip_quality(row['total_bill'], row['tip']),
axis=1
)
print("Résultat avec apply + lambda :\n",
df[['total_bill', 'tip', 'tip_quality_apply']].head(), "\n")
# ------------------------------------------------------
# Méthode 2 : np.vectorize (plus lisible et souvent plus rapide)
# ------------------------------------------------------
import numpy as np
df['tip_quality_vectorized'] = np.vectorize(tip_quality)(
df['total_bill'],
df['tip']
)
print("Résultat avec np.vectorize :\n",
df[['total_bill', 'tip', 'tip_quality_vectorized']].head(), "\n")
# ------------------------------------------------------
# Notes pédagogiques importantes
# ------------------------------------------------------
print("""
💡 Points clés à retenir :
- apply sur plusieurs colonnes nécessite axis=1
- La fonction custom doit retourner UNE seule valeur par ligne
- lambda est pratique pour des appels ponctuels
- np.vectorize rend une fonction Python "consciente" de NumPy
- np.vectorize améliore souvent la lisibilité et parfois les performances
""")
# ======================================================
# 9. Méthodes utiles : informations statistiques et tri
# ======================================================
print("=== Informations statistiques et tri de données ===\n")
# ------------------------------------------------------
# Statistiques descriptives
# ------------------------------------------------------
print("Description statistique du DataFrame :\n")
print(df.describe().T, "\n") # Transposé pour meilleure lisibilité
# ------------------------------------------------------
# Tri des données
# ------------------------------------------------------
print("Tri par pourboire (tip) croissant :\n")
print(df.sort_values('tip').head(), "\n")
print("Tri par pourboire décroissant :\n")
print(df.sort_values('tip', ascending=False).head(), "\n")
print("Tri sur plusieurs colonnes (tip puis size) :\n")
print(df.sort_values(['tip', 'size']).head(), "\n")
# ------------------------------------------------------
# Valeurs min / max et leurs index
# ------------------------------------------------------
max_total = df['total_bill'].max()
idx_max = df['total_bill'].idxmax()
min_total = df['total_bill'].min()
idx_min = df['total_bill'].idxmin()
print(f"Max total_bill = {max_total} à l'index {idx_max}")
print(df.loc[idx_max], "\n")
print(f"Min total_bill = {min_total} à l'index {idx_min}")
print(df.loc[idx_min], "\n")
# ------------------------------------------------------
# Corrélation entre colonnes numériques
# ------------------------------------------------------
print("Matrice de corrélation :\n")
print(df.corr(numeric_only=True), "\n")
# ------------------------------------------------------
# Comptage de valeurs catégorielles
# ------------------------------------------------------
print("Répartition par sexe :\n")
print(df['sex'].value_counts(), "\n")
print("Valeurs uniques pour 'day' :\n")
print(df['day'].unique(), "\n")
print("Nombre de jours uniques :")
print(df['day'].nunique(), "\n")
# ------------------------------------------------------
# Remplacement de valeurs : replace
# ------------------------------------------------------
print("Remplacement des valeurs de 'sex' avec replace :\n")
print(df['sex'].replace(['Female', 'Male'], ['F', 'M']).head(), "\n")
# ------------------------------------------------------
# Remplacement de valeurs : map (recommandé)
# ------------------------------------------------------
sex_mapping = {
'Female': 'F',
'Male': 'M'
}
print("Remplacement des valeurs de 'sex' avec map :\n")
print(df['sex'].map(sex_mapping).head(), "\n")
# ------------------------------------------------------
# Détection et suppression de doublons
# ------------------------------------------------------
print("Présence de doublons :")
print(df.duplicated().any(), "\n")
# Exemple pédagogique
simple_df = pd.DataFrame([1, 2, 2, 2], index=['A', 'B', 'C', 'D'])
print("DataFrame avec doublons :\n", simple_df, "\n")
print("Lignes dupliquées :\n")
print(simple_df.duplicated(), "\n")
print("Suppression des doublons :\n")
print(simple_df.drop_duplicates(), "\n")
# ------------------------------------------------------
# Filtrage par intervalle avec between
# ------------------------------------------------------
between_filter = df['total_bill'].between(10, 20, inclusive='both')
print("Notes totales entre 10 et 20 $ :\n")
print(df[between_filter].head(), "\n")
# ------------------------------------------------------
# nlargest et nsmallest
# ------------------------------------------------------
print("Top 5 des pourboires les plus élevés :\n")
print(df.nlargest(5, 'tip'), "\n")
print("Top 5 des pourboires les plus faibles :\n")
print(df.nsmallest(5, 'tip'), "\n")
# ------------------------------------------------------
# Échantillonnage aléatoire (sampling)
# ------------------------------------------------------
print("Échantillon aléatoire de 5 lignes :\n")
print(df.sample(5), "\n")
print("Échantillon aléatoire de 10% du DataFrame :\n")
print(df.sample(frac=0.1), "\n")
print("""
💡 Points clés à retenir :
- describe() donne une vue statistique rapide
- sort_values() permet le tri simple ou multi-colonnes
- idxmax() / idxmin() donnent la position des valeurs extrêmes
- value_counts(), unique(), nunique() sont essentiels pour les catégories
- map() est plus lisible que replace() pour de nombreux remplacements
- duplicated() et drop_duplicates() gèrent les doublons
- between(), nlargest(), nsmallest() simplifient les filtres
- sample() permet l’échantillonnage aléatoire
""")groupby
groupby() sert à regrouper des lignes partageant une même valeur (segmenter les données par catégories), puis à appliquer un calcul (mean, sum, count…) sur chaque groupe.
👉 Exactement comme en SQL
Exemple
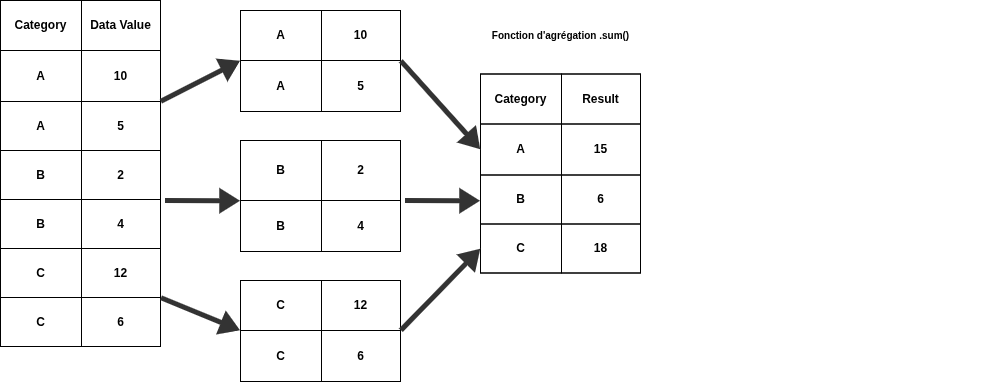
Colonnes catégorielles vs continues :
- Colonnes catégorielles : Valeurs discrètes mais peuvent être numériques ou textuelles (ex : années)
- Colonnes continues : Valeurs numériques continues
INFO
df.groupby('model_year')À ce stade :
- Aucun calcul n’est effectué
- Pandas crée un objet GroupBy en attente
- Il faut obligatoirement appeler une méthode d’agrégation
Les fonctions d’agrégation
Une fois les données regroupées, Pandas doit savoir quoi calculer. 🔹 Fonctions les plus courantes
| Méthode | Description |
|---|---|
mean() | Moyenne |
sum() | Somme |
count() | Nombre de valeurs |
size() | Taille du groupe |
min() / max() | Valeurs extrêmes |
std() | Écart-type |
var() | Variance |
describe() | Statistiques complètes |
Comprendre le MultiIndex
Lorsque tu groupes sur plusieurs colonnes, Pandas crée un index hiérarchique (MultiIndex).
Fichier Python associé
"""
dataframe_groupby.py
====================
Opérations groupby et index multi-niveaux (MultiIndex)
Ce script couvre :
- Le fonctionnement de groupby()
- Les agrégations classiques
- Le groupby sur plusieurs colonnes
- Les index hiérarchiques (MultiIndex)
- La sélection avec loc et xs
- Le tri et la manipulation des niveaux
- Les agrégations avancées avec agg()
"""
import pandas as pd
import numpy as np
# ======================================================
# 0. Chargement des données
# ======================================================
df = pd.read_csv("./data/mpg.csv")
print("=== Aperçu du DataFrame ===")
print(df.head())
print()
# ======================================================
# 1. Méthode groupby()
# ======================================================
"""
groupby() crée un objet intermédiaire.
Aucune opération n’est effectuée tant qu’une méthode
d’agrégation n’est pas appliquée.
"""
grouped = df.groupby("model_year")
print("Type de l'objet groupby :", type(grouped))
print()
# ------------------------------------------------------
# Agrégations classiques
# ------------------------------------------------------
print("=== Moyennes par année ===")
avg_year = grouped.mean(numeric_only=True)
print(avg_year)
print()
print("Index :", avg_year.index)
print("Colonnes :", avg_year.columns)
print()
print("=== Colonne mpg uniquement ===")
print(avg_year["mpg"])
print()
# Accès direct en une ligne
print("=== mpg moyen par année (one-liner) ===")
print(df.groupby("model_year").mean(numeric_only=True)["mpg"])
print()
# Statistiques descriptives
print("=== describe() par année ===")
print(df.groupby("model_year").describe())
print()
print("=== describe() transposé ===")
print(df.groupby("model_year").describe().transpose())
print()
# ======================================================
# 2. Groupby sur plusieurs colonnes
# ======================================================
print("=== Moyennes par année ET par cylindres ===")
year_cyl = df.groupby(["model_year", "cylinders"]).mean(numeric_only=True)
print(year_cyl.head())
print()
print("Index du DataFrame multi-niveaux :")
print(year_cyl.index)
print()
# ======================================================
# 3. MultiIndex (index hiérarchique)
# ======================================================
print("=== Informations sur le MultiIndex ===")
print("Niveaux :", year_cyl.index.levels)
print("Noms des niveaux :", year_cyl.index.names)
print()
# ------------------------------------------------------
# Sélection avec loc
# ------------------------------------------------------
print("=== Toutes les cylindrées pour l'année 70 ===")
print(year_cyl.loc[70])
print()
print("=== Années 70 et 72 ===")
print(year_cyl.loc[[70, 72]])
print()
print("=== Ligne unique : année 70, 8 cylindres ===")
print(year_cyl.loc[(70, 8)])
print()
# ------------------------------------------------------
# Sélection transversale avec xs()
# ------------------------------------------------------
"""
xs() (cross-section) permet de sélectionner des données
à partir d’un niveau interne du MultiIndex.
"""
print("=== Toutes les données pour l'année 70 (xs) ===")
print(year_cyl.xs(key=70, level="model_year"))
print()
print("=== Moyennes pour les moteurs 4 cylindres (toutes années) ===")
four_cyl = year_cyl.xs(key=4, level="cylinders")
print(four_cyl)
print()
"""
⚠️ Bon réflexe :
Il est souvent plus simple de FILTRER les données
avant le groupby plutôt que d’essayer de manipuler
le MultiIndex après coup.
"""
print("=== Filtrage AVANT groupby (6 et 8 cylindres) ===")
filtered = df[df["cylinders"].isin([6, 8])]
print(
filtered
.groupby(["model_year", "cylinders"])
.mean(numeric_only=True)
)
print()
# ======================================================
# 4. Manipulation des niveaux du MultiIndex
# ======================================================
# Échange des niveaux
print("=== Swap des niveaux ===")
print(year_cyl.swaplevel().head())
print()
# Tri du MultiIndex
print("=== Tri par année (descendant) ===")
print(year_cyl.sort_index(level="model_year", ascending=False).head())
print()
print("=== Tri par cylindres (descendant) ===")
print(year_cyl.sort_index(level="cylinders", ascending=False).head())
print()
# ======================================================
# 5. Agrégations avancées avec agg()
# ======================================================
"""
agg() permet d’appliquer plusieurs fonctions
d’agrégation simultanément, éventuellement différentes
selon les colonnes.
"""
# Sélection des colonnes numériques
num_df = df.select_dtypes(include="number")
print("=== Agrégations globales ===")
print(num_df.agg(["median", "mean"]))
print()
print("=== Agrégations ciblées (mpg, weight) ===")
print(num_df.agg(["sum", "mean"])[["mpg", "weight"]])
print()
print("=== Agrégations spécifiques par colonne ===")
print(
df.agg({
"mpg": ["median", "mean"],
"weight": ["mean", "std"]
})
)
print()
# ======================================================
# 6. groupby() + agg()
# ======================================================
print("=== groupby + agg() ===")
print(
df.groupby("model_year").agg({
"mpg": ["median", "mean"],
"weight": ["mean", "std"]
})
)
print()Combinaison
Dans la pratique, les données viennent rarement d’une seule source :
- plusieurs fichiers CSV
- différentes tables d’une base de données
- résultats intermédiaires de calculs
- données mensuelles / annuelles séparées
👉 Pandas propose deux grandes familles d’outils pour assembler ces données :
| Méthode | Quand l’utiliser |
|---|---|
pd.concat() | Empiler ou coller des DataFrames |
pd.merge() | Faire des jointures logiques (comme en SQL) |
Concaténation
concat() ne regarde pas le sens des données, il se contente de :
- coller des lignes ou des colonnes
- aligner automatiquement les index et colonnes
- remplir avec NaN si nécessaire
📌 Aucune logique métier, juste de l’assemblage
👉 Définition informelle
La concaténation consiste à "coller" deux DataFrames ensemble
Exemple : concaténation par colonnes
| Index | Year | Pop |
|---|---|---|
| USA | 1776 | 328 |
| CANADA | 1867 | 38 |
| MEXICO | 1821 | 126 |
| Index | GDP | Perct |
|---|---|---|
| USA | 20.5 | 75% |
| CANADA | 1.7 | NAN |
| MEXICO | 1.22 | 25% |
| Index | Year | Pop | GDP | Perct |
|---|---|---|---|---|
| USA | 1776 | 328 | 20.5 | 75% |
| CANADA | 1867 | 38 | 1.7 | NAN |
| MEXICO | 1821 | 126 | 1.22 | 25% |
Exemple : concaténation par lignes
| Index | Year | Pop | GDP |
|---|---|---|---|
| USA | 1776 | 328 | 20.5 |
| CANADA | 1867 | 38 | 1.7 |
| Index | Year | Pop | GDP |
|---|---|---|---|
| MEXICO | 1821 | 126 | 1.22 |
| BRAZIL | 1822 | 209 | 1.86 |
| Index | Year | Pop | GDP |
|---|---|---|---|
| USA | 1776 | 328 | 20.5 |
| CANADA | 1867 | 38 | 1.7 |
| BRAZIL | 1822 | 209 | 1.86 |
| MEXICO | 1821 | 126 | 1.22 |
Fusion
merge() fonctionne comme une jointure de base de données :
- il utilise une clé,à savoir how
- il compare les valeurs
- il décide quelles lignes garder
Les types de jointures
- INNER JOIN (intersection) : Garde uniquement les valeurs présentes dans les deux tables
- LEFT JOIN : Garde toutes les lignes de gauche et complète avec
NaNsi nécessaire - RIGHT JOIN : Symétrique du LEFT JOIN
- OUTER JOIN (union complète) : Garde tout ce qui existe au moins une fois
Fichier Python associé
"""
dataframe_combination.py
========================
Combinaison de DataFrames avec Pandas
Ce script couvre :
- La concaténation avec pd.concat()
- Les fusions avec pd.merge()
- Les jointures SQL-like : inner, left, right, outer
- Les fusions sur index ou colonnes différentes
- La gestion des colonnes dupliquées
"""
import pandas as pd
import numpy as np
# ======================================================
# 1. CONCATÉNATION (pd.concat)
# ======================================================
"""
La concaténation permet de "coller" des DataFrames
ayant une structure similaire.
"""
data_one = {
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']
}
data_two = {
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']
}
one = pd.DataFrame(data_one)
two = pd.DataFrame(data_two)
print("=== DataFrame ONE ===")
print(one, "\n")
print("=== DataFrame TWO ===")
print(two, "\n")
# ------------------------------------------------------
# Concaténation par lignes (axis=0) — par défaut
# ------------------------------------------------------
print("=== Concaténation par lignes (axis=0) ===")
concat_rows = pd.concat([one, two], axis=0)
print(concat_rows, "\n")
"""
⚠️ Les colonnes ne correspondent pas :
Pandas remplit automatiquement avec NaN
"""
# ------------------------------------------------------
# Concaténation par colonnes (axis=1)
# ------------------------------------------------------
print("=== Concaténation par colonnes (axis=1) ===")
concat_cols = pd.concat([one, two], axis=1)
print(concat_cols, "\n")
# ------------------------------------------------------
# Concaténation par lignes AVEC colonnes identiques
# ------------------------------------------------------
print("=== Concaténation par lignes avec colonnes alignées ===")
two.columns = one.columns # renommage C,D → A,B
concat_aligned = pd.concat([one, two], axis=0)
print(concat_aligned, "\n")
# Réinitialisation de l'index
concat_aligned = concat_aligned.reset_index(drop=True)
print("=== Index réinitialisé ===")
print(concat_aligned, "\n")
# ======================================================
# 2. FUSION (pd.merge)
# ======================================================
"""
pd.merge() fonctionne comme une jointure SQL
"""
registrations = pd.DataFrame({
'reg_id': [1, 2, 3, 4],
'name': ['Andrew', 'Bobo', 'Claire', 'David']
})
logins = pd.DataFrame({
'log_id': [1, 2, 3, 4],
'name': ['Xavier', 'Andrew', 'Yolanda', 'Bobo']
})
print("=== Registrations ===")
print(registrations, "\n")
print("=== Logins ===")
print(logins, "\n")
# ------------------------------------------------------
# INNER JOIN
# ------------------------------------------------------
print("=== INNER JOIN ===")
inner_merge = pd.merge(
registrations,
logins,
how='inner',
on='name'
)
print(inner_merge, "\n")
"""
INNER :
→ uniquement les clés présentes dans LES DEUX tables
"""
# ------------------------------------------------------
# LEFT JOIN
# ------------------------------------------------------
print("=== LEFT JOIN ===")
left_merge = pd.merge(
registrations,
logins,
how='left',
on='name'
)
print(left_merge, "\n")
"""
LEFT :
→ toutes les lignes de la table de gauche
"""
# ------------------------------------------------------
# RIGHT JOIN
# ------------------------------------------------------
print("=== RIGHT JOIN ===")
right_merge = pd.merge(
registrations,
logins,
how='right',
on='name'
)
print(right_merge, "\n")
"""
RIGHT :
→ toutes les lignes de la table de droite
"""
# ------------------------------------------------------
# OUTER JOIN
# ------------------------------------------------------
print("=== OUTER JOIN ===")
outer_merge = pd.merge(
registrations,
logins,
how='outer',
on='name'
)
print(outer_merge, "\n")
"""
OUTER :
→ union complète des deux tables
"""
# ======================================================
# 3. FUSION SUR INDEX
# ======================================================
registrations_idx = registrations.set_index("name")
print("=== Fusion index (left_index=True) ===")
merge_index = pd.merge(
registrations_idx,
logins,
left_index=True,
right_on='name',
how='inner'
)
print(merge_index, "\n")
# ======================================================
# 4. COLONNES CLÉS DIFFÉRENTES
# ======================================================
registrations_renamed = registrations.rename(columns={'name': 'reg_name'})
print("=== Colonnes différentes ===")
print(registrations_renamed, "\n")
merge_diff_cols = pd.merge(
registrations_renamed,
logins,
left_on='reg_name',
right_on='name',
how='inner'
)
print(merge_diff_cols, "\n")
# Nettoyage
merge_diff_cols = merge_diff_cols.drop('reg_name', axis=1)
print("=== Après nettoyage ===")
print(merge_diff_cols, "\n")
# ======================================================
# 5. COLONNES DUPLIQUÉES & SUFFIXES
# ======================================================
registrations_dup = registrations.rename(columns={'reg_id': 'id'})
logins_dup = logins.rename(columns={'log_id': 'id'})
print("=== Colonnes dupliquées ===")
print(pd.merge(registrations_dup, logins_dup, on='name'), "\n")
print("=== Suffixes personnalisés ===")
print(
pd.merge(
registrations_dup,
logins_dup,
on='name',
suffixes=('_reg', '_log')
)
)Pivot Tables
Les tableaux croisés dynamiques permettent de :
- Réorganiser vos données,
- Créer de nouveaux index,
- Résumer des valeurs par regroupement.
Exemple
df
| foo | bar | baz | zoo | |
|---|---|---|---|---|
| o | one | A | 1 | x |
| 1 | one | B | 2 | y |
| 2 | one | C | 3 | z |
| 3 | two | A | 4 | q |
| 4 | two | B | 5 | w |
| 5 | two | C | 6 | t |
Après pivot df.pivot(index='Foo', columns='Bar', values='Base') :
| bar | A | B | C |
|---|---|---|---|
| foo | |||
| one | 1 | 2 | 3 |
| two | 4 | 5 | 6 |
foodevient l’indexbardevient les colonnesbazest la valeur à afficher
Remarque : Les colonnes avec des valeurs uniques comme
zoosont ignorées lors du pivot.
TIP
pivot(): réorganise les données, aucune agrégation.pivot_table(): réorganise et agrège les données.
Fichier Python associé
"""
pandas_pivot_tables.py
=====================
Le pivotement des données peut aider à clarifier les relations et à explorer vos datasets.
Documentation complète sur le pivot et les méthodes connexes :
https://pandas.pydata.org/docs/user_guide/reshaping.html
"""
import numpy as np
import pandas as pd
# ======================================================
# Lecture du fichier CSV
# ======================================================
df = pd.read_csv('./data/Sales_Funnel_CRM.csv')
# ======================================================
# 1. Méthode pivot()
# ======================================================
"""
La méthode pivot() réorganise les données en fonction des valeurs de colonnes et d'un nouvel index.
⚠️ Note : Il n'est pas toujours nécessaire de pivoter les données. Cette méthode est surtout utile
pour l'analyse, l'exploration et la visualisation.
Checklist avant d'utiliser pivot() :
1. Quelle question essayez-vous de répondre ?
2. À quoi ressemblerait le DataFrame qui répond à cette question ?
3. Le pivot est-il vraiment nécessaire ?
4. Quelles colonnes sont essentielles pour le pivot ?
"""
help(pd.pivot) # Documentation rapide
# Exemple pratique : combien de licences de chaque produit Google a-t-il acheté ?
licenses = df[['Company', 'Product', 'Licenses']]
# Pivot simple
pivot_simple = pd.pivot(
data=licenses,
index='Company', # valeurs uniques de Company deviennent l'index
columns='Product', # valeurs uniques de Product deviennent les colonnes
values='Licenses' # valeurs numériques à afficher
)
pivot_simple
# ======================================================
# 2. Méthode pivot_table()
# ======================================================
"""
Comme pivot(), pivot_table() réorganise les données mais permet également d'appliquer des fonctions
d'agrégation. Très pratique pour résumer les données numériques.
"""
# Pivot table basique avec somme
pivot_sum = pd.pivot_table(df, index="Company", aggfunc='sum')
# Sélectionner uniquement les colonnes intéressantes
pivot_sum[['Licenses', 'Sale Price']]
# Ou en utilisant le paramètre 'values'
pivot_sum_values = pd.pivot_table(
df,
index="Company",
values=['Licenses', 'Sale Price'],
aggfunc='sum'
)
# Équivalent avec groupby
df.groupby('Company').sum()[['Licenses', 'Sale Price']]
# ======================================================
# Pivot multi-index
# ======================================================
pivot_multi = pd.pivot_table(
df,
index=["Account Manager", "Contact"],
values=['Sale Price'],
aggfunc='sum'
)
# Ajouter une dimension de colonne (segmentation par produit)
pivot_multi_columns = pd.pivot_table(
df,
index=["Account Manager", "Contact"],
values=["Sale Price"],
columns=["Product"],
aggfunc=np.sum,
fill_value=0 # remplace NaN par 0
)
# Plusieurs fonctions d'agrégation
pivot_multi_agg = pd.pivot_table(
df,
index=["Account Manager", "Contact"],
values=["Sale Price"],
columns=["Product"],
aggfunc=[np.sum, np.mean],
fill_value=0
)
# Plusieurs colonnes de valeurs
pivot_multi_values = pd.pivot_table(
df,
index=["Account Manager", "Contact"],
values=["Sale Price", "Licenses"],
columns=["Product"],
aggfunc=np.sum,
fill_value=0
)
# Multi-index avec Product dans l'index
pivot_full_index = pd.pivot_table(
df,
index=["Account Manager", "Contact", "Product"],
values=["Sale Price", "Licenses"],
aggfunc=np.sum,
fill_value=0
)
# Ajouter les totaux généraux avec margins=True
pivot_with_totals = pd.pivot_table(
df,
index=["Account Manager", "Contact", "Product"],
values=["Sale Price", "Licenses"],
aggfunc=np.sum,
fill_value=0,
margins=True
)
# Exemple avec autre dimension
pivot_status = pd.pivot_table(
df,
index=["Account Manager", "Status"],
values=["Sale Price"],
aggfunc=np.sum,
fill_value=0,
margins=True
)