
Base Vectorielle
Qu’est-ce qu’une base ?
Une base est un ensemble de vecteurs qui permet de décrire tous les vecteurs d’un espace vectoriel en utilisant des combinaisons linéaires de ces vecteurs. En d'autres termes, une base est comme un "système de coordonnées" pour un espace, permettant de représenter n'importe quel point ou vecteur. Une base fournit un ensemble minimal de directions indépendantes pour naviguer dans l'espace.
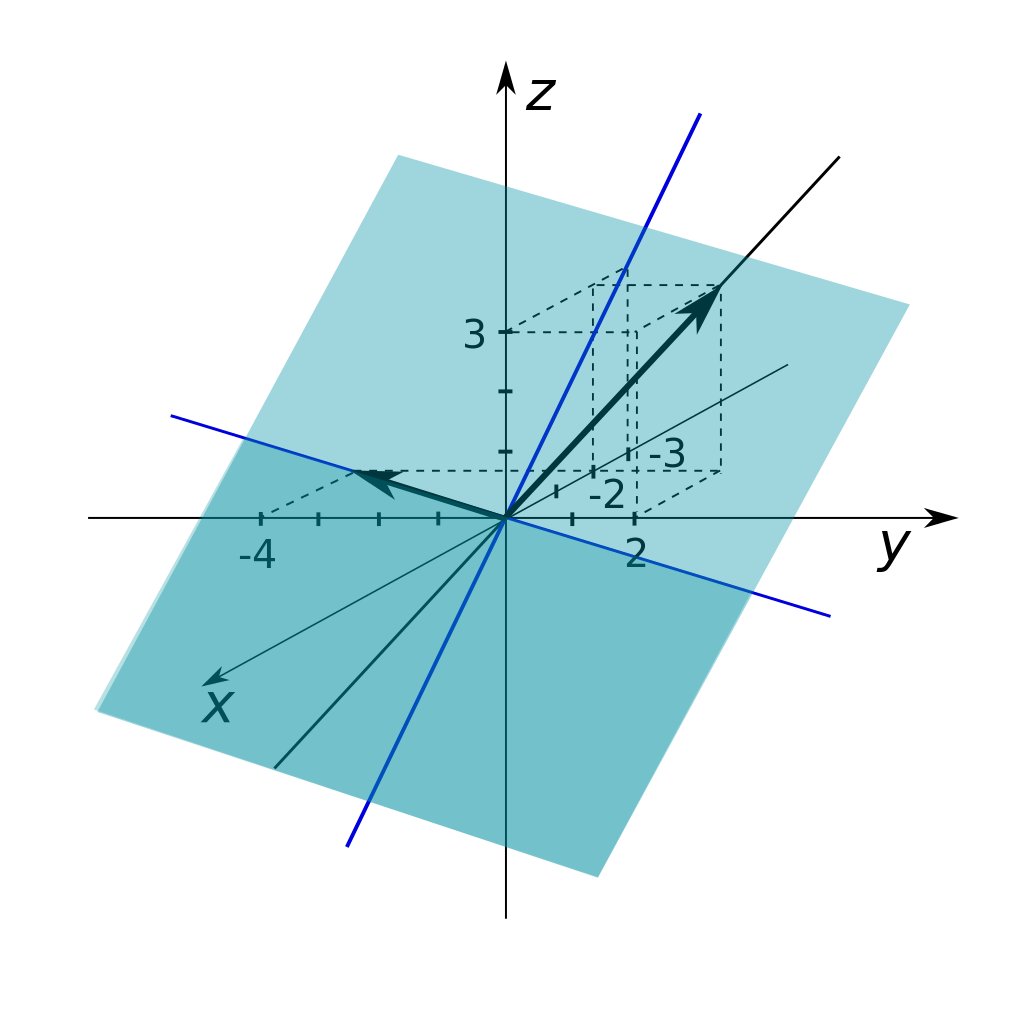
👉 Intuition
Une base est comme un ensemble minimal de "directions" qui permet de naviguer dans tout l’espace. En ML, changer de base peut simplifier les calculs, comme dans la réduction de dimensionnalité où l'on projette les données sur une base qui capture l'essentiel de l'information.
INFO
En machine learning, les bases sont essentielles pour comprendre les transformations de données, comme dans l'analyse en composantes principales (PCA) où une nouvelle base est choisie pour maximiser la variance des données, ou dans les réseaux de neurones où les couches apprennent des bases qui extraient des caractéristiques pertinentes (features) des données d'entrée.
Définition mathématique
Un ensemble de vecteurs
- Les vecteurs sont linéairement indépendants :
- Les vecteurs engendrent l’espace (ou le spannent), c’est-à-dire que tout vecteur
de l’espace peut s’écrire comme :
Le nombre
Développement : Dimension et bases multiples
Tous les espaces vectoriels de dimension finie ont plusieurs bases possibles, mais toutes les bases ont le même nombre d'éléments (théorème de la dimension). Par exemple, en
Exemples en dimensions basses
- En 1D (une ligne) : Un seul vecteur non nul
suffit. Tout vecteur sur la ligne est un multiple de . - En 2D (un plan) : Deux vecteurs indépendants
. Tout vecteur dans le plan s'écrit . - En 3D : Trois vecteurs indépendants
. Si on ajoute un non dans le plan des trois premiers, on passe à 4D. En ML, les données en haute dimension (e.g., images avec des milliers de pixels) sont souvent projetées sur une base de plus faible dimension pour réduire le bruit et la complexité.
Indépendance linéaire
Un ensemble de vecteurs est linéairement indépendant si aucun des vecteurs ne peut être exprimé comme une combinaison linéaire des autres. Autrement dit, aucun vecteur n’est "redondant". Si un vecteur est une combinaison des autres, il n'apporte pas de nouvelle direction.
Exemple
- Si
, alors est dans la même direction que et n’apporte rien de nouveau → dépendance linéaire. - Si
n’est pas un multiple de (par exemple, ils forment un angle non nul), alors ils sont indépendants et peuvent engendrer un plan (espace 2D). En ML, l'indépendance linéaire aide à détecter les features redondantes dans un dataset (e.g., via corrélation ou PCA).
Vérification de l’indépendance linéaire
Pour vérifier si des vecteurs sont linéairement indépendants, on peut :
- Former une matrice avec ces vecteurs comme colonnes.
- Calculer son déterminant (non nul = indépendance) ou vérifier son rang (égal au nombre de vecteurs = indépendance).
- En 2D, pour
, , le déterminant de la matrice est . S’il est non nul, les vecteurs sont indépendants. En data science, un rang inférieur indique des dépendances, utile pour la sélection de features.
- En 2D, pour
Pourquoi le déterminant vérifie-t-il l’indépendance linéaire ?
Le déterminant d’une matrice carrée formée par des vecteurs est un outil puissant pour vérifier leur indépendance linéaire. Voici pourquoi, étape par étape :
Définition et lien avec l’indépendance linéaire
Un ensemble de
Formons la matrice
où
Rôle du déterminant
Si
- Si
: est inversible, et le système n’a que la solution triviale . Les vecteurs sont donc indépendants. - Si
: n’est pas inversible, et le système a des solutions non triviales (des ). Cela signifie qu’au moins un vecteur est une combinaison linéaire des autres, donc les vecteurs sont dépendants.
Interprétation géométrique
Le déterminant a une signification géométrique :
- En 2D, pour deux vecteurs,
représente l’aire du parallélogramme formé par ces vecteurs. Si , l’aire est nulle, ce qui signifie que les vecteurs sont alignés (colinéaires), donc dépendants. - En 3D, pour trois vecteurs,
représente le volume du parallélépipède. Si , le volume est nul, ce qui indique que les vecteurs sont coplanaires (ou alignés), donc dépendants. En général, un déterminant nul signifie que les vecteurs ne couvrent pas tout l’espace , mais un sous-espace de dimension inférieure.
Application à l’exemple du cours
Reprenons les vecteurs
Calculons le déterminant :
- Premier mineur :
- Deuxième mineur :
- Troisième mineur :
Ainsi :
Puisque
Cas non carré
Si le nombre de vecteurs
En machine learning
Le déterminant est utilisé pour détecter les redondances dans les features (si
Résumé
Le déterminant teste l’indépendance linéaire car il mesure si les vecteurs couvrent pleinement l’espace. S’il est nul, les vecteurs sont confinés à un sous-espace, donc dépendants. S’il est non nul, ils forment une base.
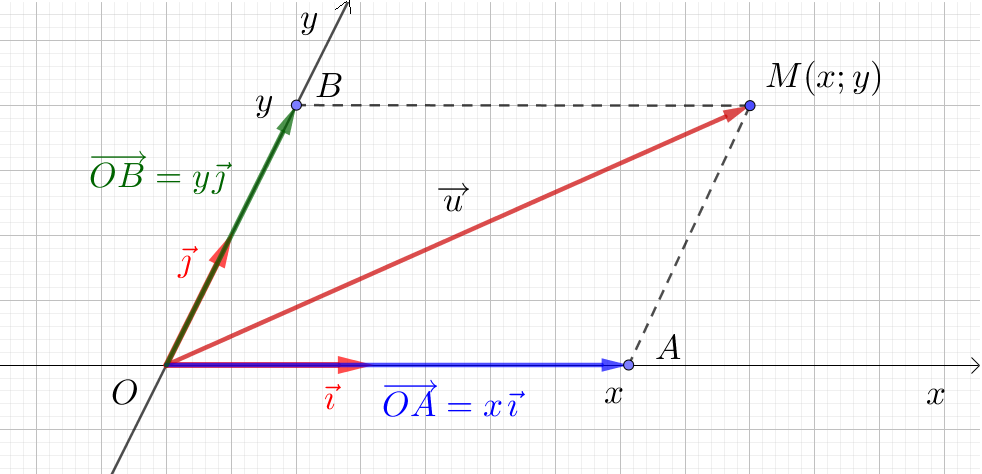
Exemple en 2D
Considérons :
, (base canonique 2D). - Ces vecteurs sont linéairement indépendants, car
implique . - Tout vecteur
peut s’écrire : .
Exemple supplémentaire : Vérification d'indépendance linéaire en 3D
Les vecteurs suivants sont-ils linéairement indépendants ?
Pour vérifier, on forme la matrice
On calcule le déterminant de
Calcul du déterminant étape par étape (utilisant la formule pour une matrice 3x3) :
- Premier mineur :
- Deuxième mineur :
- Troisième mineur :
Maintenant, assembler :
Puisque
Engendrement de l'espace (Span)
Un ensemble de vecteurs engendre l'espace s'il permet d'atteindre tout vecteur via des combinaisons linéaires. La base est l'ensemble minimal (indépendant) qui engendre l'espace.
Interprétation
Si les vecteurs n'engendrent pas l'espace, ils ne couvrent qu'un sous-espace (e.g., deux vecteurs alignés engendrent une ligne, pas un plan). En ML, le span des données peut révéler des sous-espaces de haute variance, comme dans PCA où l'on identifie les directions principales.
Exemple en ML : Réduction de dimensionnalité
Supposez des points de données alignés approximativement sur une ligne dans
Bases spéciales
Base orthonormée
Une base est orthonormée si :
- Les vecteurs sont orthogonaux deux à deux :
si . - Les vecteurs sont unitaires :
.
👉 Avantage
Les bases orthonormées simplifient les calculs en ML, notamment dans les projections (comme dans PCA) ou les transformations (e.g., matrices de rotation dans les réseaux de neurones). Elles ne doivent pas nécessairement être unitaires ou orthogonales, mais c'est plus facile si elles le sont.
Exemple de base orthonormée
La base canonique en 2D :
, . - Vérification :
- Orthogonalité :
. - Unitaire :
, .
- Orthogonalité :
Base quelconque
Une base quelconque n’est pas nécessairement orthonormée. Les vecteurs peuvent avoir des longueurs différentes et ne pas être orthogonaux.
👉 Note
Les bases non orthonormées compliquent les calculs, car les projections nécessitent des matrices de changement de base. En ML, on préfère souvent orthonormer les bases (e.g., via la décomposition QR ou SVD) pour simplifier les opérations.
Changement de base
Le changement de base consiste à réécrire un vecteur exprimé dans une base
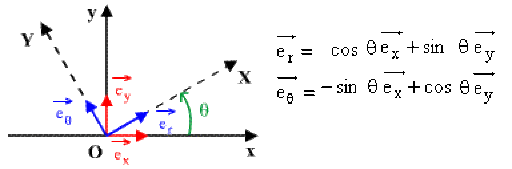
Principe
Soit un vecteur
On veut ses coordonnées dans une nouvelle base
La transformation est effectuée à l’aide d’une matrice de changement de base
Si les bases ne sont pas orthogonales, on ne peut pas utiliser seulement le produit scalaire ; il faut des matrices.
Développement mathématique
Si
Alors, pour passer de la base
Exemple en 2D
Soit une base
- Dans
: . - Pour trouver les coordonnées dans
, on résout : Cela donne le système : Solution : , . Donc, .
Exemple supplémentaire : Changement de base en 3D avec base orthogonale
Étant donné les vecteurs
Puisque la base
Détaillons les étapes :
Vérifions d'abord l'orthogonalité (bien que donné, pour complétude) :
Oui, orthogonaux.
Pour trouver
: On multiplie l'équation par (produit scalaire des deux côtés) : Puisque orthogonaux,
et , donc : Calcul :
De même pour
: Multipliez par :
Donc, dans la base
Pourquoi c’est important en Machine Learning ?
- Représentation des données : Les bases permettent de représenter les données dans des espaces de caractéristiques. En PCA, les composantes principales forment une base orthonormée qui maximise la variance des données et minimise le bruit (distance perpendiculaire comme mesure du bruit).
- Transformations linéaires : Les changements de base sont utilisés pour simplifier les calculs, comme dans les réseaux de neurones où les poids sont des matrices appliquant des transformations linéaires pour extraire des features (e.g., forme du nez, teinte de peau dans la reconnaissance faciale).
- Réduction de dimensionnalité : En ML, on utilise des bases orthonormées (via SVD ou QR) pour réduire la dimensionnalité tout en préservant les informations importantes (e.g., embeddings dans NLP). Si les données sont alignées sur une ligne, projeter sur cette direction réduit le bruit.
- Mécanisme d’attention : Dans les transformers, les matrices de changement de base (ou projections linéaires) sont utilisées pour calculer les relations entre les tokens via des produits scalaires.
Exemple concret en ML
Dans PCA, les données sont projetées sur une base orthonormée formée par les vecteurs propres de la matrice de covariance. Cela réduit la dimensionnalité tout en conservant la variance maximale, facilitant la visualisation ou la classification. Par exemple, des points alignés sur une ligne ont une variance élevée le long de la ligne et faible perpendiculairement (bruit).
👉 Application pratique
En NLP, les embeddings de mots (comme dans Word2Vec) sont souvent exprimés dans une base non orthonormée. Les algorithmes comme t-SNE ou UMAP changent de base pour visualiser ces données en 2D ou 3D. Dans les réseaux de neurones, l'apprentissage dérive une base qui extrait les caractéristiques les plus riches des données.