
Diagrammes de dispersion
Les diagrammes de dispersion, aussi appelés nuages de points (scatter plots en anglais), sont l’un des outils les plus fondamentaux en analyse exploratoire des données (EDA). Ils permettent de visualiser la relation entre deux variables continues.
Variables continues vs variables catégorielles
Variables continues
Une variable continue est une variable numérique qui peut prendre une infinité de valeurs possibles dans un intervalle (âge, taille, salaire, température, prix, distance etc.)
Exemple
Un âge de 28 ans peut être affiné :
- 28 ans
- 28 ans et 2 mois
- 28 ans, 2 mois et 1 semaine
➡️ On peut toujours diviser l’unité de mesure.
Variables catégorielles
Une variable catégorielle représente des catégories distinctes et non continues.
Exemple
- niveau d’éducation (lycée, bachelor, master)
- couleur (rouge, vert, bleu)
- forme (carré, triangle, cercle)
- noms (Marc, Claire, Vincent)
➡️ Il n’existe pas de valeur intermédiaire entre deux catégories.
À quoi sert un diagramme de dispersion ?
Un diagramme de dispersion permet de :
- visualiser la relation entre deux variables continues
- détecter des tendances
- identifier des corrélations
- repérer des valeurs aberrantes (outliers)
Exemple conceptuel
Imaginons une entreprise avec des commerciaux. Variables disponibles :
- Salaire (numérique continu)
- Ventes annuelles (numérique continu)
- Expérience professionnelle
- Niveau d’éducation
❓ QUESTION : existe-t-il une relation entre le salaire et les ventes ?
VISUALISATION
Chaque point représente un employé.
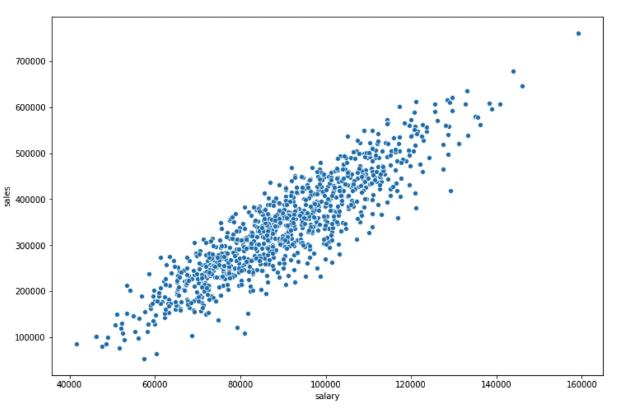
- Axe X → salaire
- Axe Y → ventes
Si les points montent globalement vers la droite, cela suggère une relation positive : plus les ventes sont élevées, plus le salaire tend à augmenter.
Seaborn peut ensuite ajouter de la couleur et du style 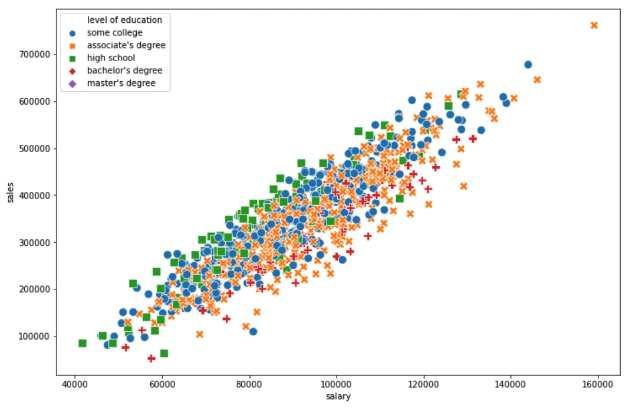
Fichier Python associé
scatter-plots
"""
===========================================================
Diagrammes de dispersion (Scatter Plots) avec Seaborn
===========================================================
Les diagrammes de dispersion (scatter plots) permettent de visualiser
la relation entre deux variables numériques.
Ils sont utiles pour :
- analyser une corrélation
- observer des tendances
- détecter des valeurs aberrantes (outliers)
Ce script explore la fonction seaborn.scatterplot() ainsi que ses
principaux paramètres : hue, size, style, palette, etc.
"""
# ===========================================================
# Imports
# ===========================================================
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# ===========================================================
# Chargement des données
# Source : http://roycekimmons.com/tools/generated_data
# ===========================================================
df = pd.read_csv("./data/dm_office_sales.csv")
print(df.head())
print("\n")
df.info()
# ===========================================================
# Scatterplot simple
# ===========================================================
sns.scatterplot(
x="salary",
y="sales",
data=df
)
plt.show()
# ===========================================================
# Paramètres Seaborn : hue (couleur)
# ===========================================================
# La couleur des points dépend d'une variable catégorielle.
plt.figure(figsize=(12, 8))
sns.scatterplot(
x="salary",
y="sales",
data=df,
hue="division"
)
plt.show()
plt.figure(figsize=(12, 8))
sns.scatterplot(
x="salary",
y="sales",
data=df,
hue="work experience"
)
plt.show()
# ===========================================================
# Palette de couleurs
# ===========================================================
# Utilisation d'une palette Matplotlib :
# https://matplotlib.org/stable/tutorials/colors/colormaps.html
plt.figure(figsize=(12, 8))
sns.scatterplot(
x="salary",
y="sales",
data=df,
hue="work experience",
palette="viridis"
)
plt.show()
# ===========================================================
# Paramètres Scatterplot : size
# ===========================================================
# Dimensionne la taille des points selon une variable numérique.
plt.figure(figsize=(12, 8))
sns.scatterplot(
x="salary",
y="sales",
data=df,
size="work experience"
)
plt.show()
# ===========================================================
# Taille fixe des marqueurs (s)
# ===========================================================
plt.figure(figsize=(12, 8))
sns.scatterplot(
x="salary",
y="sales",
data=df,
s=200
)
plt.show()
plt.figure(figsize=(12, 8))
sns.scatterplot(
x="salary",
y="sales",
data=df,
s=200,
linewidth=0,
alpha=0.2
)
plt.show()
# ===========================================================
# Paramètre style
# ===========================================================
# Applique des styles de marqueurs selon une variable catégorielle.
# Il est possible de définir ses propres marqueurs avec markers=[].
plt.figure(figsize=(12, 8))
sns.scatterplot(
x="salary",
y="sales",
data=df,
style="level of education"
)
plt.show()
# Combinaison de hue + style sur la même variable
plt.figure(figsize=(12, 8))
sns.scatterplot(
x="salary",
y="sales",
data=df,
hue="level of education",
style="level of education",
s=100
)
plt.show()
# ===========================================================
# Exporter une figure Seaborn
# ===========================================================
plt.figure(figsize=(12, 8))
sns.scatterplot(
x="salary",
y="sales",
data=df,
hue="level of education",
style="level of education",
s=100
)
plt.savefig("example_scatter.jpg")
plt.show()